
Transformer 的编码器变成了 BERT,解码器变成了 GPT。BERT 推动过去几年搜广推算法增长,而 GPT 促成了今天 GenAI 浪潮的爆发。这篇发表于 2017 年的论文,对今天产生了难以估量的影响。
论文翻译
摘要
主流 seq2seq 模型是基于编解码器架构实现的复杂 RNN 或 CNN 网络,其中表现最好的模型还会使用注意力机制来连接编码器和解码器。我们提出一种全新的简单网络架构:Transformer。它完全基于注意力机制,不使用 RNN 和 CNN。在两个机器翻译任务上的实验表明,它拥有更好的并行度,并且训练时间大大减少。在 WMT 2014 英德翻译任务上,我们的模型取得了 28.4 的 BLEU 分数,比现有最好模型提升 2 BLEU。在 WMT 2014 英法翻译任务上,我们的模型在 8 台 GPU 上训练 3.5 天后,在单一模型评分指标下获得 41.8 的最高分。相比之前文献的最佳模型,Transformer 极大降低了训练成本。我们还通过英语成分句法分析任务展示了 Transformer 的泛化能力,无论数据集大小,Transformer 都能很好地泛化到其他任务上。
1. 介绍
循环神经网络、长短记忆网络和门控循环网络被证明是序列模型和处理语言建模和机器翻译这类转换问题的最先进方法。在此之后,人们又花费大量努力挖掘循环神经网络语言模型和编解码器架构的潜力。
循环神经网络对输入输出词元按位置进行计算,将词元的位置与时间步进行对齐,生成一系列隐状态 $h_t$。该隐状态是前一个隐状态 $h_{t-1}$ 和时间步 $t$ 时刻输入 $X_t$ 的函数。在训练样本时,这种内在的序列关系天然阻碍并行。对长序列文本,因为内存限制了批量样本的处理,导致这种阻碍更加明显。最近的研究利用因子分解和条件计算两种方法显著提升了计算效率,尤其后者还提高了模型的性能。但是序列计算这个最根本的限制依然存在。
注意力机制在多种序列建模和转换建模任务中占有重要地位,它能对输入输出序列中的依赖关系进行位置无关的建模。除了少数几个例子外,注意力机制通常和循环神经网络一起使用。
我们提出了 Transformer,一种不使用循环神经网络、纯基于注意力来捕获输入输出全局依赖关系的模型。Transformer 显著提高了并行度,并且在 8 台 P100 GPU 上训练 12 小时后,翻译质量达到了前所未有的高度。
2. 背景
减少序列计算同样是优化 Neural GPU, ByteNet 和 ConvS2S 模型的基础,这些模型使用卷积神经网络作为最基本的块(即 Block,我们将整体具有某种功能的多层神经元称为一个块儿,比如做自注意力的块儿叫作 Self-Attention Block),为所有输入输出位置并行计算其隐含表示。在这些模型中,关联任意两个输入输出位置词元所需的操作数量随距离的增加而增长,ConvS2S 是线性增长,而 ByteNet 是对数增长,这使得学习长距离依赖变得困难。在 Transformer 中,这种操作的运算次数被缩减为常数。尽管对基于位置的注意力做加权平均会(在长距离上)减小有效分辨率,但我们在 3.2 节提出的多头注意力缓解了这个问题。
自注意力,有时被称为内部注意力,是指抽取一个序列上不同位置的词元间依赖关系的注意力机制。计算自注意力是为了更好地表征该序列。自注意力已经成功运用在多种任务中,包括阅读理解、摘要总结、文本推演、以及学习任务无关的通用句子表征。
基于注意力机制的端到端记忆网络,相比序列对齐的循环神经网络,在简单的问答任务和语言建模上表现更好。
在我们的认知里,Transformer 是首个基于自注意机制计算输入输出的表征,且不使用序列对齐的 RNN 或 CNN 的 seq2seq 模型。接下来的章节,我们将阐述使用自注意力的原因,并探讨为什么它比 Neural GPU, ByteNet 和 ConvS2S 这类模型更好。
3. 模型架构
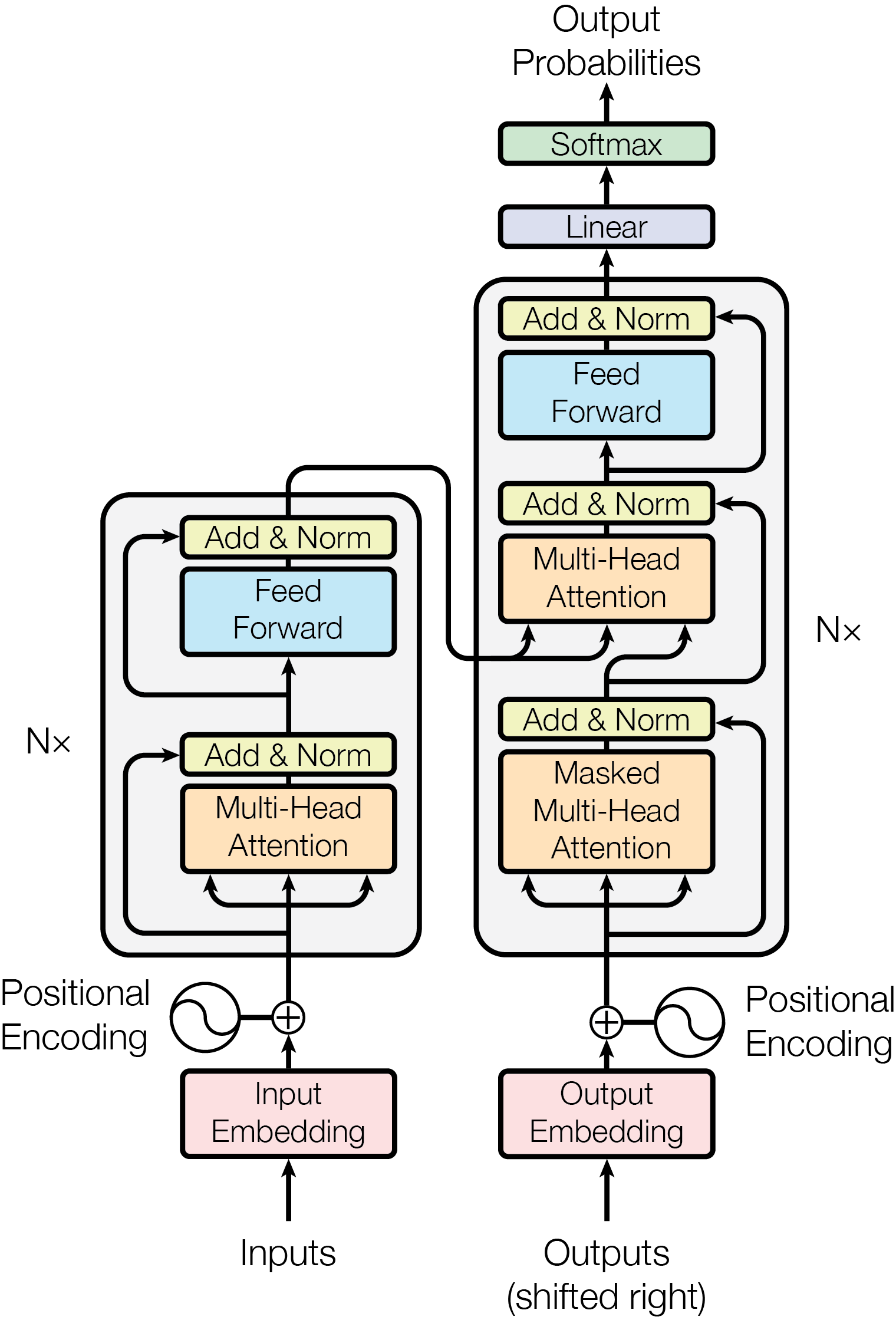
大多数有竞争力的神经网络序列转换模型都有编码器-解码器结构。这里,编码器将输入序列中词元的表征 $(x_1, …, x_n)$ 映射到一个连续的表征序列 $\mathbf{z} = (z_1, …, z_n)$. 对于给定的 $\mathbf{z}$,解码器输出一个序列 $(y_1, …, y_m)$,每次只输出一个元素。每次迭代,模型都在做自回归。它将上一轮生成的词元作为输入,用于生成下一个的词元。
Transformer 遵循这种整体架构,分别在编码器和解码器中使用堆叠的自注意力和逐点的全连接层,如上图左右两边所示。
3.1 编码器和解码器
编码器:
编码器由 N = 6 个完全相同的块组成,每个块里有两个子层。第一个是多头注意力机制层,第二个是基于位置的全连接前馈网络层。对两个子层,我们都是先做残差连接,再做层归一化(layer normalization)。每个子层的输出都是 $LayerNorm(x + Sublayer(x))$,其中 $Sublayer(x)$ 是每个子层自己的具体实现。为了满足残差连接的使用条件,模型内的所有子层和嵌入层都使用相同维度的输出 $d_{model} = 512$.
解码器:
解码器同样由 N = 6 个完全相同的块组成。除了编码器中有的两个子层,解码器使用了第三个子层。第三个子层在编码器堆栈的输出中计算多头注意力。和编码器类似,我们先对每个子层做残差连接,再做层归一化。我们还修改了解码器中的自注意力子层,以防读取到后续序列。掩码机制的使用,加上每次输出只偏移一个位置的事实,保证了位置 i 的预测只能基于小于 i 的位置的输出。
3.2 注意力
注意力函数可以理解为一个查询和一系列键值对到一个输出的映射,这里查询、键和值都是向量,输出是值的加权和。每个值所分配的权重由查询和对应键的兼容性函数计算得出。查询和所有键做点积,然后除以 $d_k$,然后给上面这坨东西包一层 softmax 以获取每个值的权重。
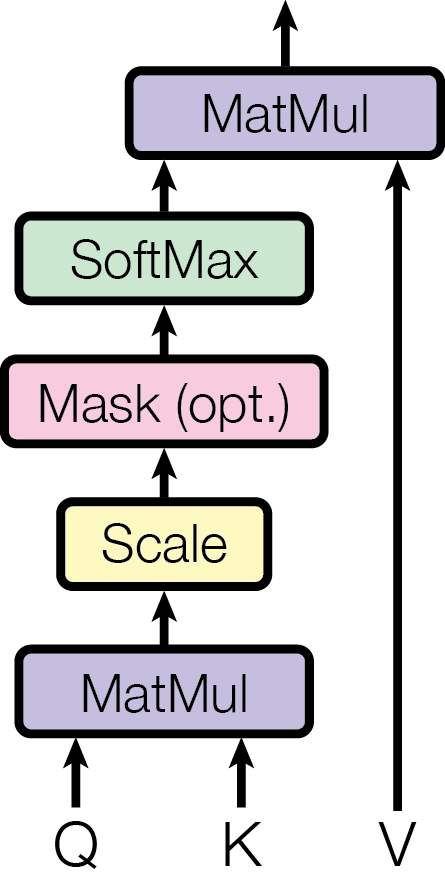
3.2.1 放缩点积注意力
我们给本文使用的注意力起名为“放缩点积注意力”。输入里的查询和键都是 $d_k$ 维的,值是 $d_v$ 维的。我们计算查询向量和所有键向量的点积,将结果除以 $d_k$,然后应用 softmax 函数以获取值的权重。
在实践中,我们同时在一组查询上计算注意力,将这组查询打包成矩阵 $Q$. 键向量和值向量也打包成矩阵 $K$ 和 $V$. 结果矩阵计算如下:
$$\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{d_k}\right) V$$
最常用的两种注意力是加性注意力和点积注意力。我们的算法几乎就是点积注意力,但加了个放缩因子 $\frac{1}{d_k}$. 加性注意力使用具有单个隐藏层的前馈网络计算兼容性函数。尽管两者理论复杂度接近,但在实践中,点积注意力更快且更省空间。因为它可以通过高度优化的矩阵乘法代码实现。
对于较小的 $d_k$ 两种机制表现相似,但在 $d_k$ 的值较大时,加性注意力比未放缩的点积注意力表现得更好。我们怀疑对于较大的 $d_k$ 值,点积会变得很大,导致 softmax 函数进入梯度极小的区域。为了抵消这种效应,我们通过 $\frac{1}{d_k}$ 对点积进行缩放。
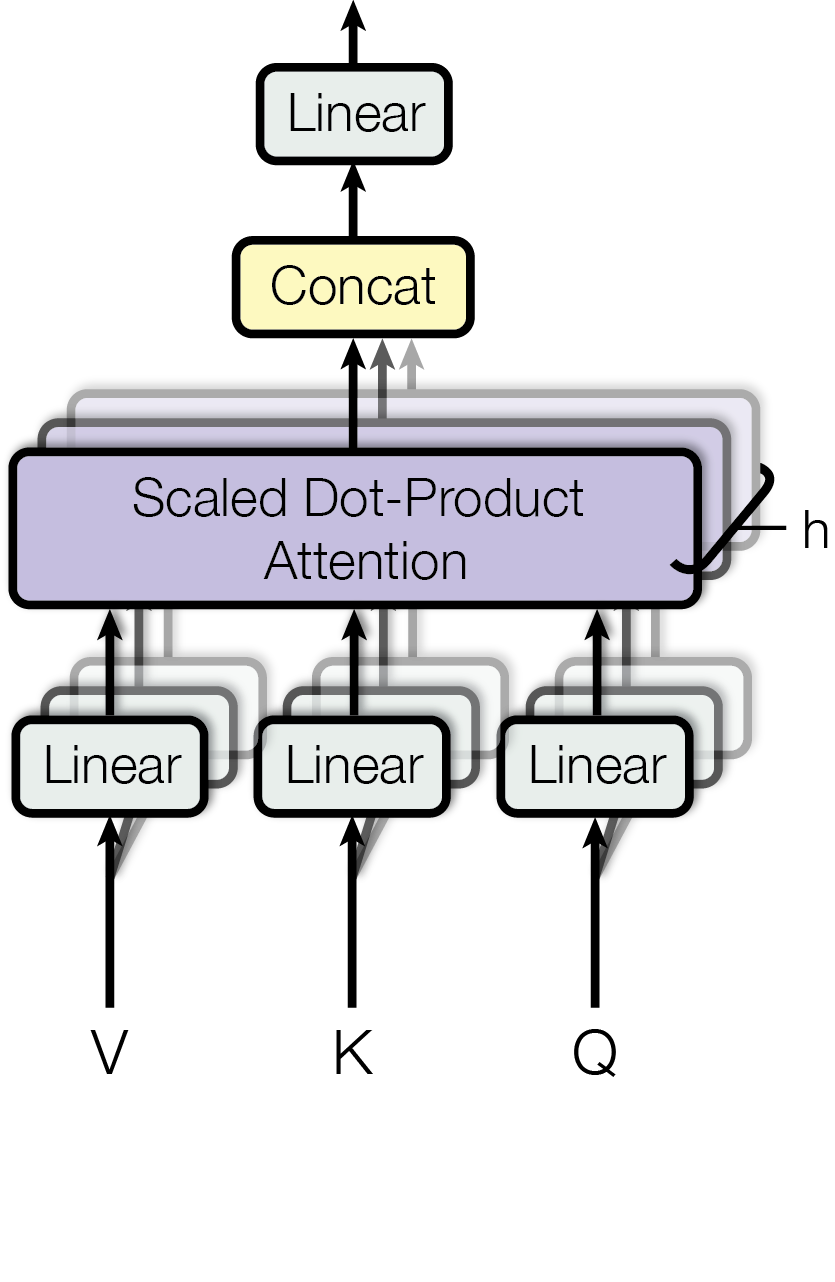
3.2.2 多头注意力
我们发现,与使用 $d_{model}$ 维 QKV 的单一注意力相比,使用不同的、由学习得到的线性变换将 QKV 分别投影到 $d_k$, $d_k$, $d_v$ 维。我们并行地在这些投影后的 QKV 上计算注意力函数,得到 $d_v$ 维的输出值。将输出值连接起来 (concatenated) 并再次投影,得到最终的值。
TODO: 施工中
后日谈
最近看论文的感受是需要一群追得上业界最新进展的人对领域进行深入的研究,这样当一种理论潜力耗尽时,最佳的优化方向就是提出一种彻底颠覆之前做法的新架构。万一新架构成功,就能带来新一波技术红利。而如果老架构仍有潜力,大部分聪明的脑袋还是会去挖老架构的潜力,因为这是最优的!
最近看到好多新方向,包括 mamba 和 MatMul-free。过去几年深度学习在底层技术上并没有跨越式的发展。最近成果的本质还是基于对 next token 的无监督学习和 Scaling Law 产生的效果。Transformer 的潜力差不多挖尽了,也许新技术就快要来了吧!
参考
arXiv: Attention Is All You Need