
SynchroTrap 是基于 Jaccard 相似度和最大连通子图的异常检测算法,出自 Facebook 的论文 Uncovering Large Groups of Active Malicious Accounts in Online Social Networks.
GitHub 项目地址:SynchroTrap
本文做了什么:
- 用
mimesis生成源数据,并基于源数据构造正态分布的样本 - 通过构造一个 $\lambda$ 可调的泊松过程,生成用户到访时间戳
- 提供一个由 7 个变量控制的异常数据生成函数,见 gen_attack_df
- 用 Jaccard 相似度构图,再用
NetworkX对图做可视化 - 用 Spark 的
graphframes计算最大连通子图 - 复现了论文 2.2 节的可视化效果,见 评估与可视化
- 介绍如何使用
Docker构建 Spark 开发环境
✨ 注意:运行以下代码依赖 utils.py 文件和 gen_data 库。
一、样本生成
脱离互联网企业,我们很难拿到可供挖掘的异常数据样本。一种方法是自己生成。自己生成样本的好处是能拿到真正的 ground truth,而且可以精细地控制异常的规模和程度。
- 生成源数据
- 生成大盘数据
- 生成正态样本分布
- 生成 uid 并计算访问次数
- 时间与时间戳
- 用户日志表
- 生成异常数据
- 选择攻击开始时间
- 获取 ip 池
- 发起攻击
- 整合两份数据
Note: 与异常捕获的难度有关的变量:
- 攻击持续的时间
attack_duration- 正常 ip 的含量
normal_ip_rate- 资源池的大小
ip_num- 资源池的隔离
uid_repeat_rate- 攻击间隔
max_t - min_t- 攻击线程数
epoch
二、算法实现
SynchroTrap 通过构建 <U, T, C> 三元组来衡量用户与用户间的距离。U 代表用户,T 代表时间,C 代表限制项。
- SynchroTrap 的原理:
- 如果两条日志的时间差小于 $T_{\text {sim }}$,且限制项 $C_i$ 与 $C_j$ 相等的比例较高,则认为 $U_i$ 和 $U_j$ 有关联。当使用多个字段作为限制项时,uid 之间的相似度可由 Jaccard similarity 给出
- 由于存在资源复用,一个 uid 往往对应多个限制项
C。比如,当多个 uid 使用同一个 IP 池,且 IP 池容量有限,那么 uid 之间的 Jaccard 相似度,会因 IP 复用而提高 - 通过对相似 uid 建边,并作连通图,能发现更高层次的 uid 的连接,并将其纳入同一个社区。这样作出的社区,如果社区规模特别大,就说明这个社区是有问题的。因为一般情况下,不会存在如此大规模的资源复用
- 用 Jaccard 相似度建边
- 可视化
- 计算强连通图
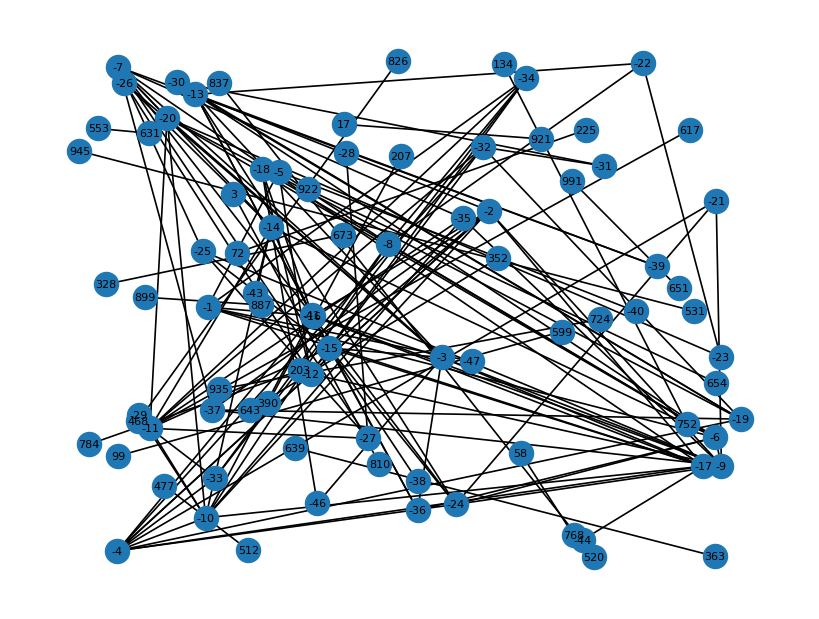
三、评估与可视化
- 异常检测:
- 由于存在资源复用,坏人的 uid 之间的 Jaccard similarity 相似度较高。用高度相似的节点构图,并计算社区。我们发现,坏人用户的社区规模,通常比正常用户的社区规模大得多。
- 模型评估:
- 计算 SynchroTrap 算法的准确率、精确率、召回率等指标
- 可视化:
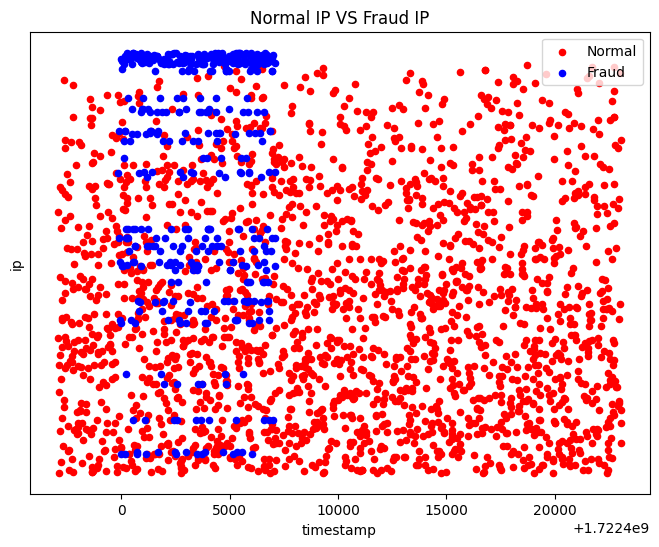
- 鉴于 SynchroTrap 是一种识别同步行为的算法。我们可以用 ip 和 timestamp 作图,看看能否发现黑产攻击的起停时间
下图中,Fraud IP 表示我们识别出的坏人 IP,Normal IP 表示未被识别的 IP(包含未召回部分)
附录1:部署 Spark 环境
- 使用 Docker 安装 Spark 环境
- 下载 Docker 镜像
- 启动一个 Docker 容器
- Docker 常用命令
- 在 Docker 中使用 Spark
- 在本地浏览器访问 Jupyter Lab
- 检查 Spark 是否已安装
- 启动 PySpark
附录2:运行 Spark
- 检查 Spark 环境
- 安装 & 使用 graphframes
- 定制 Python 环境
参考