
2023 年本地部署大模型的报价近千万,2024 年初便骤降至百万,如今是 2025 年,只需要一行 vLLM 命令就可以部署大模型,人工成本几近于零。
GitHub 项目地址:llm-deploy
本文内容包括:
- 3 种方式部署 DeepSeek R1:Ollama, vLLM 和 Transformers
- 使用 vLLM 部署 Qwen2.5 模型
- 安装 Open WebUI 作为本地模型的前端聊天框
- 通过
vllm serve实现一行代码启动 vLLM 推理服务
✨ 快速部署说明在 /deploy,vLLM 服务启动脚本在 /server.
一、本地部署 DeepSeek R1
大模型本地部署依赖推理引擎,目前比较流行的推理引擎有:
| 推理引擎 | 场景 | 介绍 |
|---|---|---|
| Ollama | 适合个人开发者和轻量级应用 | 基于 llama.cpp 开发,支持 CPU 推理,安装简单,开箱即用,适合快速原型开发和测试 |
| vLLM | 适合高并发生产环境 | 支持多 GPU 并行、批处理、PagedAttention,吞吐量高,延迟低,适合大规模服务部署 |
| Transformers | 适合模型研究和实验 | 提供完整的模型训练和推理接口,支持模型微调、量化、加速,适合研究人员和需要深度定制的场景 |
| SGLang | 适合需要复杂推理流程的场景 | 支持结构化输出、并行推理、流式输出,特别适合需要多轮对话和复杂推理的应用 |
| LMDeploy | 适合企业级部署和边缘计算 | 由上海人工智能实验室开发,提供完整的模型量化、加速和部署工具链,支持多种硬件平台,特别适合资源受限场景 |
下面介绍如何部署 Ollama, vLLM, Transformers 这三款推理引擎,简要部署步骤见本项目的 deploy 目录。
目录:
- Ollama
- vLLM
- 安装 miniconda
- 安装 jupyterlab
- 为 vllm 创建虚拟环境,并绑定到 jupyterlab
- 安装 vLLM 及相关依赖
- 下载模型文件
- 启动 jupyterlab
- 验证 vLLM
- Transformers
二、本地部署 Qwen2.5
模型名带 Instruct 说明该模型是经过指令调优(Instruction Tuning)的版本,专为理解和执行用户指令优化,适合对话生成、任务导向型场景。
部署前要先下载模型文件:
# 安装 huggingface_hub
pip install -U huggingface_hub
cd model
huggingface-cli download \
--resume-download Qwen/Qwen2.5-1.5B-Instruct \
--local-dir ./Qwen2.5-1.5B-Instruct
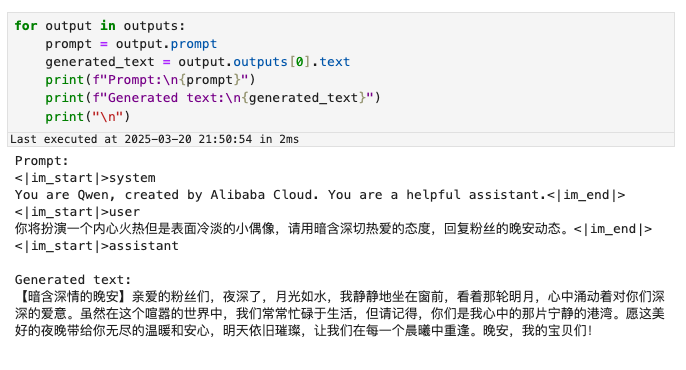
推理效果:
三、Open WebUI 作为前端聊天框
第一节我用 3 种方式部署本地大模型:Ollama, vLLM 和 Transformers.
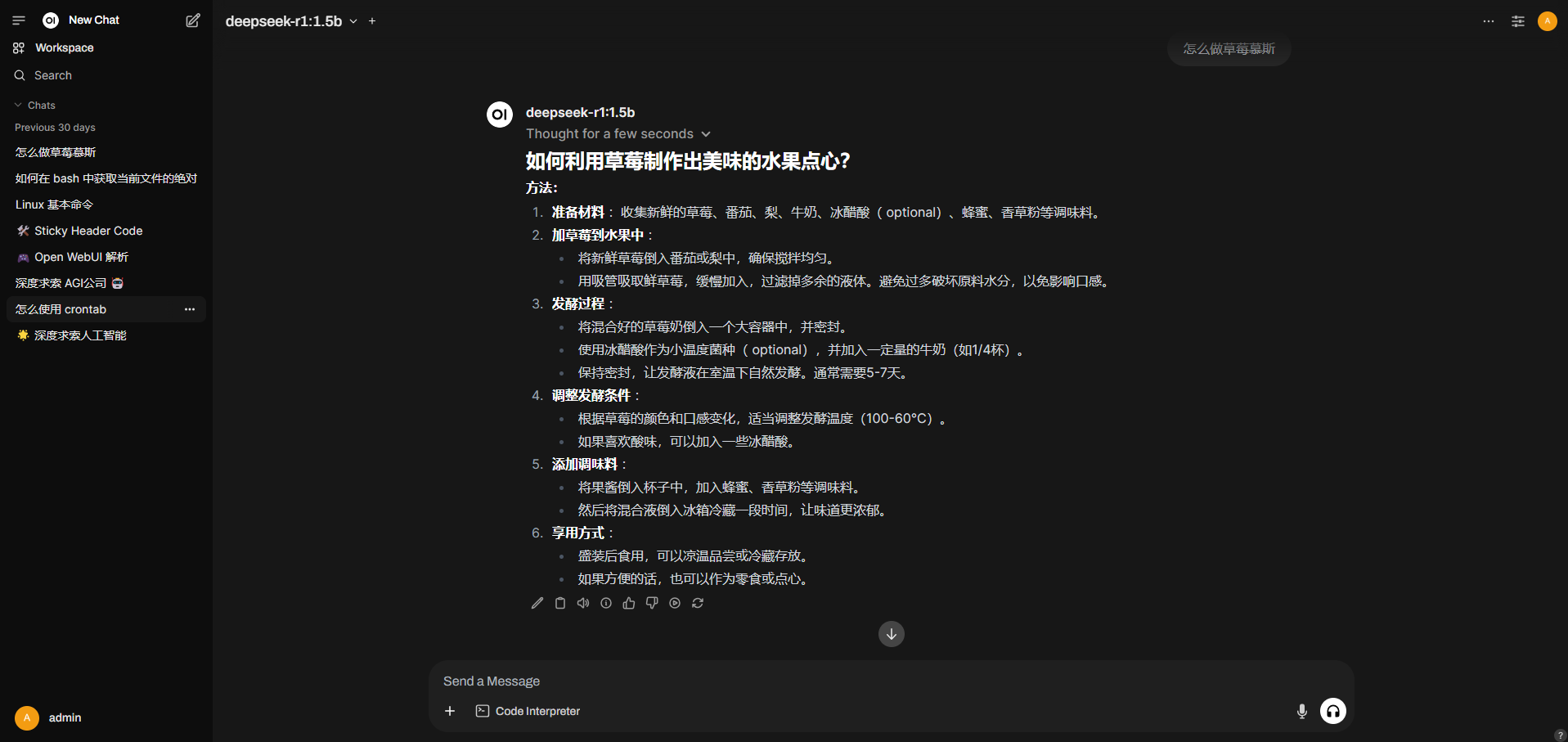
有了本地部署的大模型作为推理后端,还要连接到前端聊天框,才算是完整。开源聊天框有很多,比如 AnythingLLM, LM Studio. 比较了一圈,姑且使用 Open WebUI. 它有预开发的账号系统和历史记录,支持快速开发 RAG 和联网搜索。
它的界面长这样:
目录:
- 安装 Open WebUI
- 检查 Docker 环境
- 下载镜像
- 创建容器
- 打开前端页面
- 为 WebUI 配置推理后端
- Ollama
- vLLM
四、vLLM 推理服务
vLLM 官方支持一行 bash 命令,启动 API 服务:
vllm serve [YOUR MODEL or MODEL PATH]
当然对于不同的模型,启动参数也略有不同,需要做一定的配适。比如对于 deepseek-r1 这类推理模型,必须添加参数 --enable-reasoning --reasoning-parser deepseek_r1。具体每个模型如何使用 vLLM,可参考 vLLM 官方文档或模型文档。
PS: vLLM 的 API 服务遵循 OpenAI 的接口协议。
目录:
- DeepSeek-R1
- 启动服务端
- 运行客户端
- Qwen
- 启动服务端
- 运行客户端
- 符合 OpenAI 接口协议的 API 服务
- 强制清理显存缓存
参考:
- vLLM 仓库: vllm-project/vllm
- vLLM 文档: docs.vllm.ai
- self-llm: datawhalechina/self-llm