
在上一篇博客《LightGBM 工程实践》中,我把通用函数写到 util.py 文件,以实现代码复用。但是这么复用好麻烦,每次开新项目,得把 util.py 文件贴过去才行。为了省下这个贴的动作,我把它写成 Python 包了。现在下载一次,就可以到处使用啦!
GitHub 项目地址:flameai
一、简单介绍
我的这个包叫 FlameAI。作为一个深度学习工具包,它的主要功能是 数据预处理 和 模型评估。FlameAI 旨在解决最后一公里问题。即在框架之外,业务代码之内,寻求最佳实践。为了让我的包看起来上流一点,我让 Kimi 帮我想了几个名字,最后还是选择了 FlameAI,因为这个名字最霸气。
执行以下命令安装 FlameAI:
pip install flameai
如果嫌安装速度慢,可以使用腾讯源或阿里源:
# 腾讯源
pip install flameai -i https://mirrors.cloud.tencent.com/pypi/simple/
# 阿里源
pip install flameai -i https://mirrors.aliyun.com/pypi/simple/
如果发现 pip 缓存目录占用了太多磁盘空间,可执行以下命令(通常不需要清理)
# 清理 pip 缓存文件
pip cache purge
二、模块功能介绍
2.1 二分类模型评估
二分类模型评估是咱们的拳头产品。只需一行命令,就可以计算下面全部指标:
accuracy: 准确率precision: 精确率recall: 召回率f1_score: 精确率和召回率的调和平均数auc: ROC曲线下的面积cross-entropy loss: 交叉熵损失True Positive (TP): 真阳True Negative (TN): 真阴False Positive (FP): 假阳False Negative (FN): 假阴confusion matrix: 混淆矩阵
1)简单用法
你可以直接指定阈值,下面代码中指定阈值为 0.5。
Note: 这里的阈值指二分类模型划分正负样本的阈值。对每个样本,模型输出一个概率值,一般而言,若概率小于阈值,则判为负类;若大于等于阈值,则判为正类。
import flameai
# y_true 是真实标号,y_pred 是模型预测标号为 1 的概率
y_true = [0, 0, 0, 1, 0, 1, 0, 1, 1, 0]
y_pred = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
# 一行命令,计算全部指标
flameai.eval_binary(y_true, y_pred, threshold=0.5)
输出:
threshold: 0.50000
accuracy: 0.70000
precision: 0.60000
recall: 0.75000
f1_score: 0.66667
auc: 0.70833
cross-entropy loss: 4.03816
True Positive (TP): 3
True Negative (TN): 4
False Positive (FP): 2
False Negative (FN): 1
confusion matrix:
[[4 2]
[1 3]]
2)对阈值寻优
你也可以不设定阈值,让 FlameAI 帮你寻找最优阈值。你只需要做设定优化目标就好了,FlameAI 会帮你找。
FlameAI 内置四个目标函数,分别是:
- 准确率:
Metric.ACCURACY - 精确率:
Metric.PRECISION - 召回率:
Metric.RECALL - f1 分数:
Metric.F1_SCORE
下面这个例子在参数空间搜索最优阈值,以使精确率最大化。
from flameai import eval_binary, Metric
y_true = [0, 0, 0, 1, 0, 1, 0, 1, 1, 0]
y_pred = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
# 以最大化精确率为目标,对阈值寻优
eval_binary(y_true, y_pred, metric=Metric.PRECISION)
3)定义返回值
有时候,你想在代码中使用最优阈值,且不希望结果打印到标准输出。这可以通过设置 ret 和 verbose 参数实现:
from flameai import eval_binary, Metric
y_true = [0, 0, 0, 1, 0, 1, 0, 1, 1, 0]
y_pred = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
y_label, threshold = eval_binary(y_true,
y_pred,
metric=Metric.F1_SCORE,
ret=True, # 返回预测标号和阈值
verbose=0) # 不打印评估指标
print(f'y_label: {y_label}')
print(f'threshold: {threshold:.3f}')
输出:
y_label: [0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
threshold: 0.378
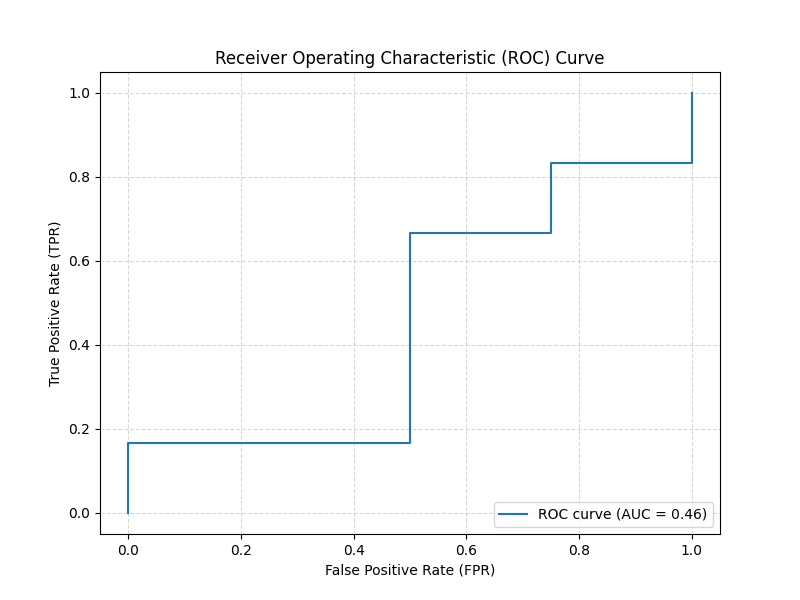
2.2 绘制 ROC 曲线
运行以下代码绘制 ROC 曲线:
from flameai.plot import roc_curve
y_true = [0, 1, 1, 0, 1, 1, 0, 0, 1, 1]
y_score = [0.1, 0.4, 0.35, 0.8, 0.15, 0.35, 0.2, 0.7, 0.05, 0.9]
roc_curve(y_true, y_score)
绘制效果:
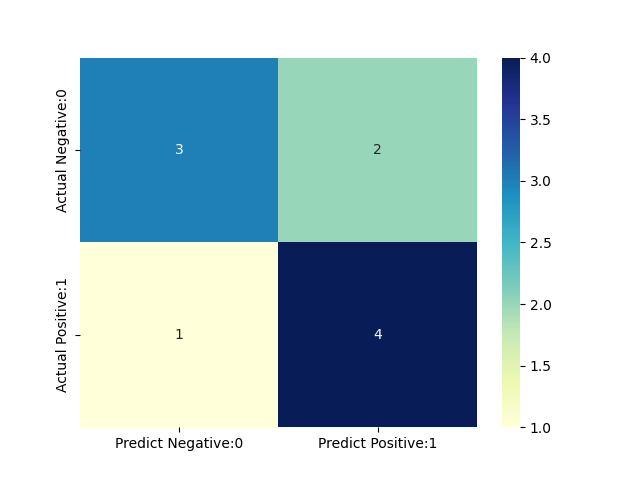
2.3 绘制混淆矩阵
运行以下代码绘制混淆矩阵:
from flameai.plot import confusion_matrix
y_true = [0, 1, 1, 0, 1, 1, 0, 0, 0, 1]
y_label = [1, 1, 1, 0, 1, 0, 0, 0, 1, 1]
confusion_matrix(y_true, y_label)
绘制效果:
2.4 线性回归模型评估
eval_regression 函数可输出三个线性回归评估指标,分别是:
- mae: 平均绝对误差
- mse: 均方误差
- r2_score: 确定系数
运行以下代码,对回归模型的结果进行评估:
import flameai
# y_true 是真实值,y_pred 是预测值
y_true = [0.10, 0.20, 0.30, 0.40, 0.50, 0.60, 0.70, 0.80, 0.90, 1.00]
y_pred = [0.11, 0.23, 0.29, 0.45, 0.50, 0.59, 0.72, 0.76, 0.94, 1.00]
flameai.eval_regression(y_true, y_pred)
输出:
mae: 0.02100
mse: 0.00073
r2_score: 0.99115
2.5 数据预处理
下面是我实现的野生 DataLoader,它是 torch.utils.data.DataLoader 的简化版本。它复刻了官方 DataLoader 的关键特性:每次调用索引从零开始迭代。凭此特性,DataLoader 能够在多轮训练中重复获取样本。
from flameai.preprocessing import DataLoader
dt = DataLoader([1, 2, 3, 4, 5])
for i in dt:
print(i)
for i in dt:
print(i)
dt.data = [1, 2, 3]
print([e for e in dt])
我的实现很简单,只有 23 行:
class DataLoader:
def __init__(self, lst: list):
self.i = 0
self._data = lst
@property
def data(self):
return self._data
@data.setter
def data(self, lst: list):
self._data = lst
def __iter__(self):
self.i = 0
return self
def __next__(self):
if self.i < len(self._data):
self.i += 1
return self._data[self.i - 1]
else:
raise StopIteration
PS: 装饰器所在的两个函数不是必须的。如果把它们去掉,还能变得更短
2.6 Hive 命令行工具
FlameAI 提供了一个 Hive 命令行工具,支持把 hql 文件的查询结果,输出到同名 csv 文件。下面是一个例子:
假设你已经把 HQL 查询语句写到 query.hql 文件里了。执行以下命令,将执行查询,并把查询结果输出到 query.csv 文件。
hve query
2.7 标准日志输出
FlameAI 支持用内部预设的 logging 模版输出日志。
from flameai.util import set_logger
logger = set_logger(__name__)
logger.error('This is an error message!')
logger.warning('This is an warning message!')
直接运行,输出大概长这样:
2024-05-25 23:23:27 ERROR [__main__]: (set_logger:<module>(5)) - This is an error message!
2024-05-25 23:23:27 WARNING [__main__]: (set_logger:<module>(6)) - This is an warning message!
如果在模块中使用,__main__ 会变成当前文件的无后缀文件名,module 会变成模块名。