本文探讨如何在 DNN 模型中天级更新聚类特征时,保持聚类标签的稳定性。
GitHub 项目地址:label-assignment
本文的主要内容包括:
- 使用
BLIP-2将图片转为 embedding - 使用匈牙利算法建立重训练标签到原标签的映射
- 开发以 样本重合率 为度量的方法
- 开发以 类心距离 为度量的方法
- 赋予 embedding 近似聚类 ID 的方法:最近邻法
时至今日,多塔模型仍以 ID 类特征为主。将模型特征以 raw data 的形式直接送入模型,效果往往不好。因此,我们通常先将特征 ID 化,然后用 mmh3 哈希打散后,再送入模型。其中,特征 ID 化 是一个重要步骤,如果 ID 的粒度太细,细到极致相当于每个样本一个 ID,这时样本就无法和与之相似的样本通过 ID 进行交互;如果 ID 的粒度太粗,则 ID 下的样本过多,此时模型无法从中学到指向足够明确的信息。
将模型特征 ID 化有很多方法,比如 聚类(无监督)、分类(有监督)、量化等等。本文仅讨论 聚类算法 及其在深度学习模型中的应用。
一、引子:频繁变更索引的代价
为了理解聚类算法产生的聚类 ID 是如何在深度模型中发生作用的,有必要介绍一下 嵌入层 (Embedding Layer) 的工作原理。
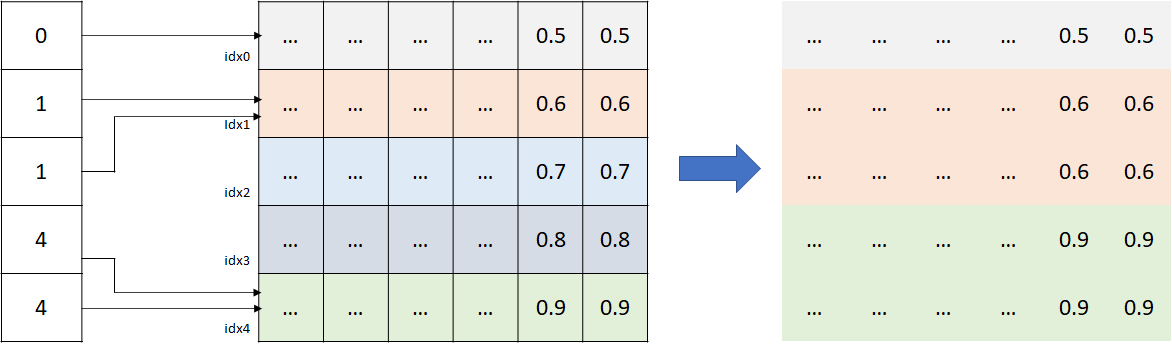
嵌入层是聚类 ID 与深度模型连接的桥梁。嵌入层的输入是聚类 ID,输出是该聚类 ID 对应的 embedding。在嵌入层中,聚类 ID 的每个枚举值都对应一个可学习的 embedding。如下图,假设聚类 ID 有 5 个枚举值 [0, 1, 2, 3, 4],枚举值对应的索引分别为 idx0, idx1 … idx4。当一个样本进入模型,它会根据聚类 id 号(比如 2 号)去找对应的索引(idx2),然后将索引下的 N 维 embedding 取回。嵌入层在有些地方也被称为码本 (codebook).
嵌入层的 embedding 是可学习的。随着模型训练的进行,索引对应的 embedding 会不断被反向传播带来的梯度更新,这就是 表示学习 的过程。在搜索、广告、推荐业务中,历史上模型关于这个聚类 ID 的“知识和经验”,都会积累在该 ID 对应的 embedding 上。
聚类算法有个特点:模型输出和输入的全集有关。具体表现为,模型每次算出来的簇,即使簇内样本完全相同,用于标识该簇的聚类 ID 也可能发生变化。举例来说,今天叫 “3 号” 的簇,明天训练可能叫 “7 号”。这可要了亲命了。模型特征每天都在变,如果每次训练,同一个簇都会被映射到不同的聚类 ID,那么这个聚类 ID 绑定的 embedding 其实是用来"表示"别的簇的,此时这个 embedding 实际学不到关于该簇的任何东西,在模型推理中必然产生反效果。因此,我们需要做一些开发,将簇持续映射到一个稳定的聚类 ID 上,多塔模型才能够正常运行。
如何将簇稳定地映射到一个聚类 ID 上,本文介绍了两种方法:
- 使用匈牙利算法进行标签重匹配
- 使用最近邻算法进行近似赋值
二、使用 BLIP-2 生成图片 Embedding
为了获取用于聚类的 Embedding,我们用 CIFAR-100 数据集作为图片来源,然后用 BLIP-2 模型生成图片的 Embedding。
Huggingface: Salesforce/blip2-opt-2.7b
BLIP-2 (Bootstrapping Language-Image Pre-training 2) 是 Salesforce 研究院于 2023 年提出的多模态模型。它由三部分组成:
- 图像编码器(类似 CLIP 的视觉模型):用于提取图像特征
- 查询变换器(Q-Former):作为连接图像与文本的桥梁
- 大型语言模型(LLM,如 OPT-2.7B):用于生成文本
BLIP-2 训练时,冻结图像编码器和大语言模型的参数,仅优化 Q-Former,这样既能充分利用已有的单模态能力,又能有效提升图文模型的交互效率。Q-Former 作为连接两个模态的桥梁,通过查询学习将视觉特征转换为与语言模型相兼容的表示,从而实现高效的跨模态对齐。
- 下载 CIFAR-100 数据集
- 下载 BLIP-2 模型文件
- 计算图片 Embedding
- 验证 BLIP-2 服务端代码
- 开发 BLIP-2 客户端代码
三、聚类标签重匹配的两种度量
可以用两种度量做重训练标签到原标签的匹配:
- 样本重合率
- 类心距离
样本重合率 的问题是不同标签的样本量不同,这意味着不同标签的敏感性是不同的。如果样本量较高,我们就有较高的置信水平认为该重合率可信;若样本量较低,这种匹配可能不置信。使用 类心距离 可以避免这个问题,在整个度量空间中,类心距离不会因标签的不同有所偏倚,是一种相对公平的匹配方法。
因此,类心距离看起来更适合作为度量。但想了想,我还是决定两种方法都尝试一下。因为并非所有聚类都有"类心"。比如,对于物品 ITEM,很可能只有标签,没有类心。这时,样本重合率作为更通用的解决方案,便彰显其价值。下面我们来开发这两种标签重匹配方法。
- 初次训练与重训练标签
- 样本重合率
- 类心距离
四、近似赋值:最近邻法
有一种方法工程难度较低,在 DNN 模型允许的情况下,可以这么开发。我把它称为 最近邻法。它的原理很简单:给定邻域 eps,若新加入 embedding 在某个簇的聚类中心的 eps 邻域范围内,则归该簇;否则 embedding 单独建簇。
下面我们把它拆解为具体的开发步骤。
1)初始化
- 用 dbscan 计算每个 embedding 样本的簇 ID
- 当样本的簇 ID 为 -1 时,说明该样本为离群点,为该样本生成一个与现有簇 ID 不重复的数作为簇 ID
- 计算每个簇的聚类中心
- 创建两个 DataFrame:
- 聚类标签表:列名为 item_id, embeddings, cluster_id
- 聚类中心表:列名为 cluster_id, cluster_center
2)更新
- 当有新 embedding 进入时,计算 embedding 是否在任一簇的聚类中心的 eps 邻域内:
- 如果在,让 embedding 加入该簇,然后更新该簇的聚类中心
- 如果不在,创建一个新簇,该 embedding 自己作为聚类中心
- 更新两个 DataFrame 表,即 聚类标签表 和 聚类中心表
为什么说它是一种近似方法,我画两张图大家就了解了。
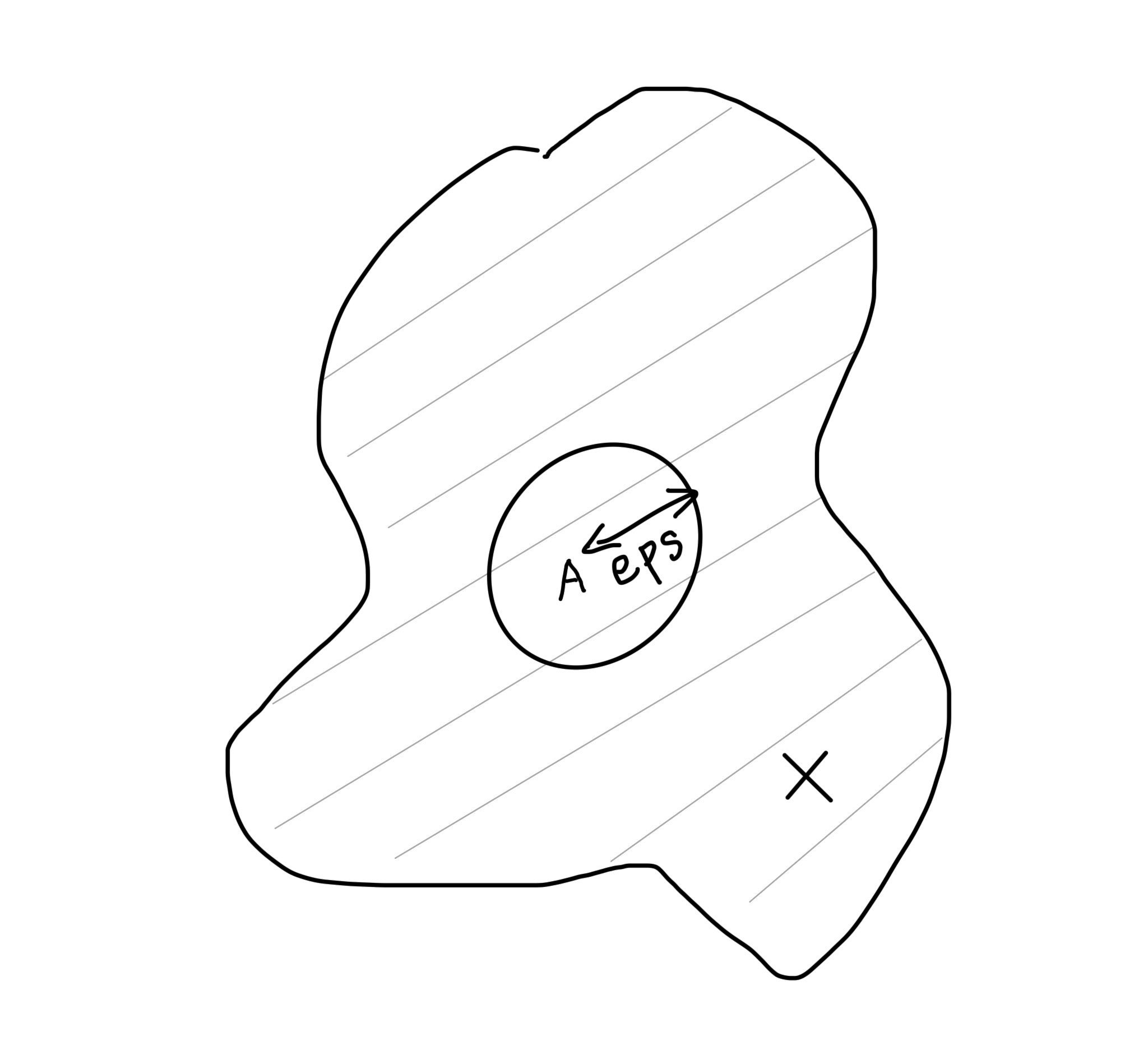
1)错失样本 X
第一张图如下,阴影部分是真正的聚类范围,聚类范围内的所有点都属于该簇。对于后续进入的新样本 X,由于我们认为只有聚类中心 A 的 eps 邻域内的点才是该簇的点,所以 X 不会被判定为该簇的点,但实际上 X 应该是该簇的点。结果莫名其妙,X 生成了一个新簇。
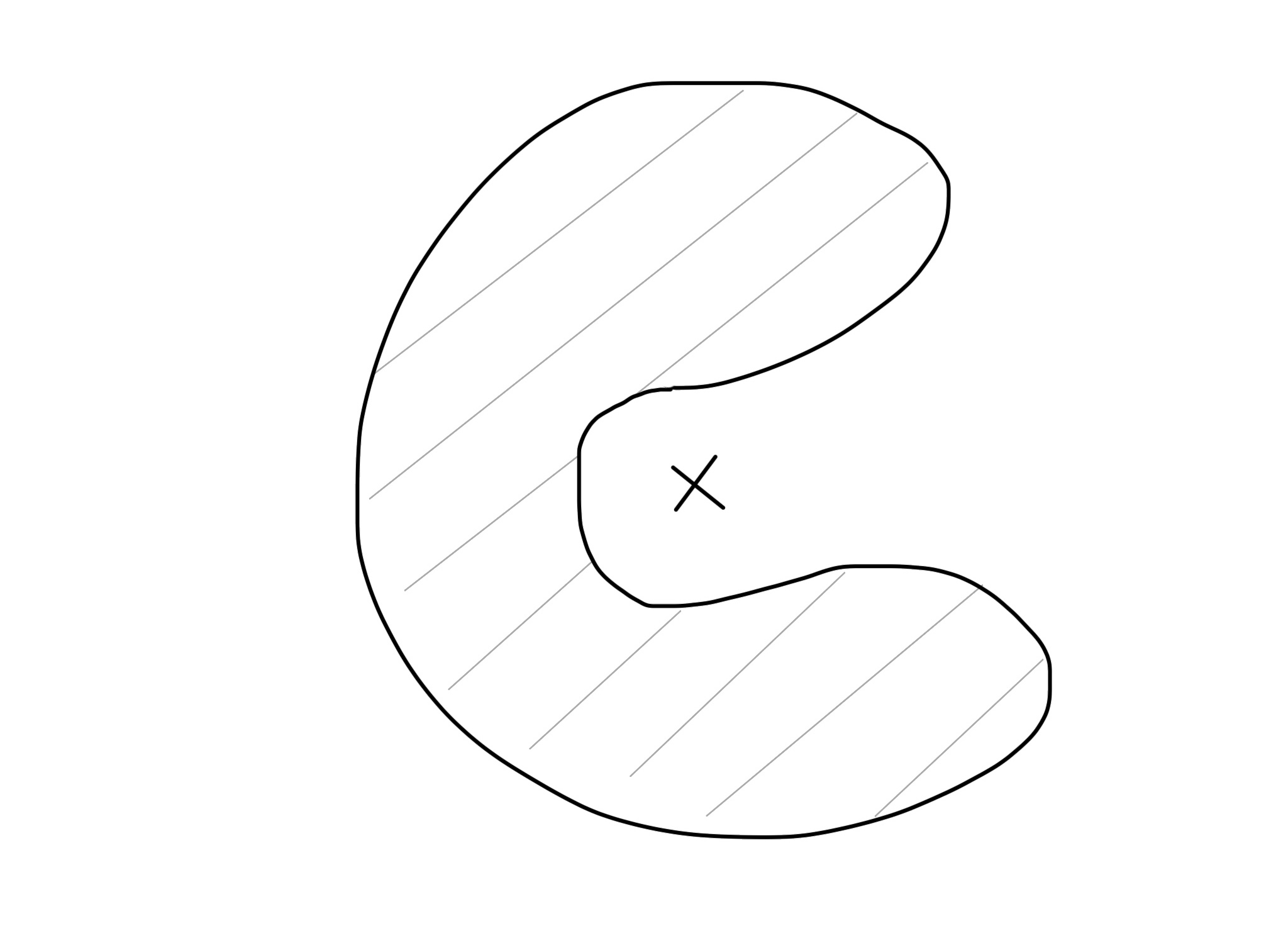
2)聚类中心不属于簇
聚类中心是由簇内各点求平均得到的,考虑到 dbscan 可能形成任意非凸形状,聚类中心可能不属于该簇,遑论聚类中心的 eps 邻域,可能根本就和这个聚类没有关系。如果出现这种情况,那不是近似,而是完全的错误了。