
统计学中有两大学派,频率学派和贝叶斯学派。频率派用总体信息和样本信息进行统计推断。而贝叶斯派除了使用以上两种信息之外,还使用先验信息进行统计推断。本文从数学原理和编程实践两个方向探究贝叶斯方法。
本文从数学原理和编程实践两个方面来介绍贝叶斯方法。
数学原理
贝叶斯理论包含很多内容。我们熟悉的利用先验分布推后验分布的方法被称为贝叶斯推理(Bayesian inference)。此外,还可以利用参数的后验分布的均值作为该参数的点估计,这种方法被称为贝叶斯估计(Bayesian estimation)。本文数学原理部分主要介绍贝叶斯推理和贝叶斯估计。
理论部分为六节,各节的主要内容如下。
| 章节 | 主要内容 |
|---|---|
| 第一节 | 用一个简单的实例,让大家对贝叶斯方法有一个形象的认识。 |
| 第二节 | 用一个复杂的实例,让大家对贝叶斯方法的术语有一个形象的认识。 |
| 第三节 | 介绍贝叶斯公式的事件形式及其推导。 |
| 第四节 | 介绍贝叶斯公式的密度函数形式及其推导。 |
| 第五节 | 介绍贝叶斯估计。 |
| 第六节 | 探索联合分布蕴含了哪些信息。 |
一、实例:癌症化验的准确率
下面请各位做题家们做一下你们最爱的经典老题 
📖 题目
有两个可选的假设:
病人有癌症(cancer)、病人无癌症(normal)
可用数据来自化验结果:
正(+)、负(-)
有先验知识:
在所有人口中,患病率是 0.8%。对确实有病的患者的化验准确率为 98%,对确实无病的患者的化验准确率为 97%,总结如下:
$ P(cancer) = 0.008, P(normal) = 0.992 \\ P(+ | cancer) = 0.98, P(- | cancer) = 0.02 \\ P(+ | normal) = 0.03, P(- | normal) = 0.97 $
问题:
假定有一个新病人,化验结果为正,是否应将病人断定为有癌症?求后验概率 $ P(cancer | +) $。
✍️ 解答
根据贝叶斯公式:
$ P(cancer | +) = \frac{P(+ | cancer) P(cancer)}{P(+)} $
其中 $ P(+) $ 为:
$ \begin{aligned} P(+) &= P(+ | cancer) P(cancer) + P(+ | \sim cancer) P(\sim cancer) \\ &= P(+ | cancer) P(cancer) + P(+ | normal) P(normal) \end{aligned} $
故:
$ \begin{aligned} P(cancer | +) &= \frac{P(+ | cancer) P(cancer)}{P(+ | cancer) P(cancer) + P(+ | normal) P(normal) } \\ &= \frac{0.98 \times 0.008}{0.98 \times 0.008 + 0.03 \times 0.992} \\ &\approx 0.209 \end{aligned} $
二、实例:史蒂文的真实身份
本节意在用一个稍微复杂的例子介绍贝叶斯公式中各个术语的含义。下面这个例子来自书籍《贝叶斯方法:概率编程与贝叶斯推断》。
史蒂文被描述为一个害羞的人,他乐于助人,但是他对其他人不太关注。他非常乐见事情处于合理的顺序,并对他的工作十分细心。你会认为史蒂文是一个图书管理员还是一个农民呢?从上面的描述来看大多数人都会认为史蒂文看上去更像是图书管理员,但是这里忽略了一个关于图书管理员和农民的事实:男性图书管理员的人数只有男性农民的 1/20。所以从统计学来看史蒂文更有可能是一个农民。
为什么我们要用贝叶斯方法
如果我们不知道对史蒂文的描述,单纯依照统计学概率,史蒂文是图书管理员的概率为 1/21。但如果我们需要量化这类描述对史蒂文是图书管理员的最终概率的影响,就要用到贝叶斯方法。
我们假设:
- 事件
A:史蒂文是一个图书管理员。 - 事件
~A: 史蒂文不是一个图书管理员,即史蒂文是一个农民。 - 事件
X: 获得对认定史蒂文是一个图书管理员有利的描述信息。
根据贝叶斯公式:
$$ P(A | X) = \frac{P(X | A) P(A)}{P(X)} $$
$ P(A) $ 容易理解,$ P(X) $ 和 $ P(X | A) $ 是什么呢?
(1)对 $ P(X | A) $ 的理解
$ P(X | A) $ 可以被定义为在史蒂文真的是一个图书管理员的情况下,史蒂文的邻居们给出某种描述的概率。如果史蒂文真的是一个图书管理员,那么我们很有可能获得对认定史蒂文是一个图书管理员有利的描述信息。这个值可能接近于1。假设它为 0.95。
(2)对 $ P(X | \sim A) $ 的理解
一般,图书管理员都拥有细心的品质、做事有规律这样的品质,但拥有这些品质的不一定是图书管理员。理解了它们之间的充分必要关系,就很容易理解某些农民同样担得起邻居们这样的描述。因此 $ P(X | \sim A) $ 接近于 0 的程度应该比 $ P(X | A) $ 接近于 1 的程度为轻。假设它为 0.1。
(3)对 $ P(X) $ 的理解
$ P(X) $ 是事件“获得对认定史蒂文是一个图书管理员有利的描述信息”的先验概率。它的值可以用已知信息计算出来:
根据全概率公式,我们有:
$$ P(X) = P(X | A)P(A) + P(X | \sim A)P(\sim A) $$
又因为:
$ P(A) $史蒂文是一个图书管理员的先验概率,已知为$ \frac{1}{21} $;$ P(\sim A) $史蒂文不是一个图书管理员的先验概率。值为$ 1 - P(A) = \frac{20}{21} $;-
$ P(X | A) $史蒂文是图书管理员的情况下,邻居给出有利于认定史蒂文是图书管理员的概率。假设为$ 0.95 $;
$ P(X | \sim A) $史蒂文不是图书管理员的情况下,邻居给出有利于认定史蒂文是图书管理员的概率。假设为$ 0.1 $;
所以:
$$ \begin{aligned} P(X) &=P(X | A) P(A)+P(X | \sim A) P(\sim A) \\ &=0.95 \times \frac{1}{21} + 0.1 \times \frac{20}{21} \\ &\approx 0.14 \end{aligned} $$
(4)$ P(A | X) $ 的计算
$$ \begin{aligned} P(A | X) &= \frac{P(X | A) P(A)}{P(X)} \\ &= \frac{0.95 \times \frac{1}{21}}{0.14} \\ &\approx 0.32 \end{aligned} $$
这个值远大于使用统计学方法计算出的概率 $ \frac{1}{21} \approx 0.05 $。使用贝叶斯方法计算出的概率更接近于获得新描述后,我们认定史蒂文是图书管理员的实际概率。
探索:假设值对后验概率的影响
(1)代码
在上述计算中,我们分别将 $ P(X | A) $ 和 $ P(X | \sim A) $ 假设为 $ 0.95 $ 和 $ 0.1 $。在这两个值是猜出来的,缺乏科学依据。为了进一步探索这两个值在其他情况下对后验概率的影响。我们用 Python 对照了不同取值情况下出现的结果。
(2)测试结果
对照组:
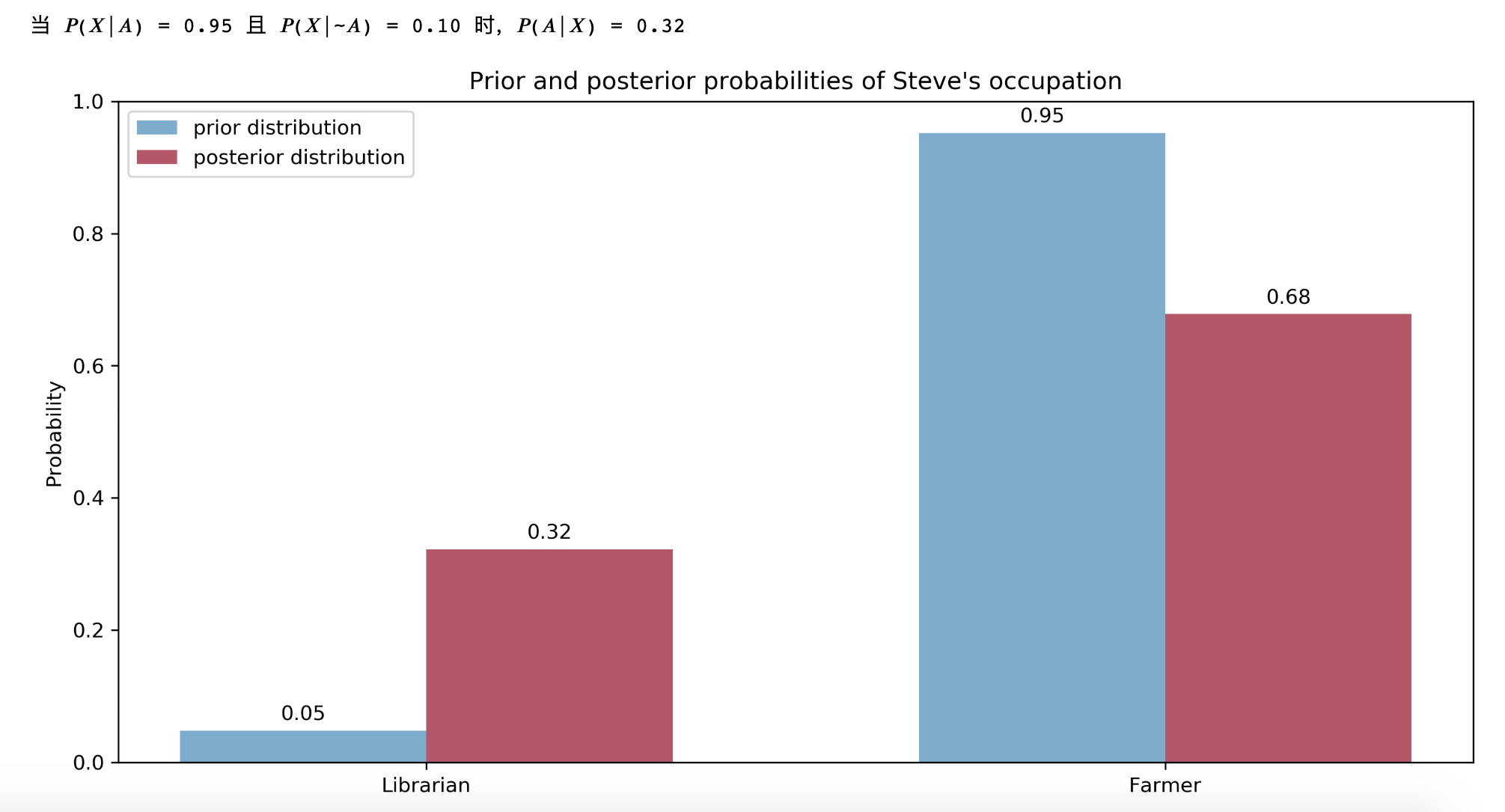
实验组:
$ P(X | A) $ 增大时,$ P(A | X) $ 增大:
-increase.png)
$ P(X | A) $ 减小时,$ P(A | X) $ 减小:
-decrease.png)
$ P(X | \sim A) $ 增大时,$ P(A | X) $ 减小:
-increase.png)
$ P(X | \sim A) $ 减小时,$ P(A | X) $ 增大:
-decrease.png)
分别调整 $ P(X | A) $ 和 $ P(X | \sim A) $ 的值。我们发现,当 $ P(X | A) $ 的值越大,$ P(X | \sim A) $ 的值越小时,$ P(A | X) $ 的值就越大。
(3)数学解释
我们将贝叶斯公式变换一下形式,
$$ P(A | X) = \frac{P(A) P(X | A)}{P(X | A)P(A) + P(X | \sim A) P(\sim A)}. $$
其他参数不变,$ P(X | \sim A) $ 越小,$ P(A | X) $ 的值就越大,
$$ P(A | X) \uparrow = \frac{P(A) P(X | A)}{P(X | A)P(A) + P(X | \sim A) \downarrow P(\sim A)}. \uparrow $$
其他参数不变,$ P(X | A) $ 越大,$ P(A | X) $ 的值就越大,
$$ \begin{aligned} P(A | X) \uparrow &= \frac{P(A) P(X | A)}{P(X | A)P(A) + P(X | \sim A) P(\sim A)} \\ &= \frac{1}{1 + \frac{P(X | \sim A) P(\sim A)}{P(X | A) \uparrow P(A)} \downarrow }. \uparrow \end{aligned} $$
Note: 在上述问题中,
$ P(A) $被称作先验概率,$ P(A | X) $被称作后验概率。
探索:先验概率对后验概率的影响
在其他参数不变的情况下,先验概率 $ P(A) $ 越大,后验概率 $ P(A | X) $ 就越大。
$$ \begin{aligned} P(A | X) \uparrow &= \frac{P(A) P(X | A)}{P(X | A)P(A) + P(X | \sim A) P(\sim A)} \\ &= \frac{1}{1 + \frac{P(X | \sim A) P(\sim A) \downarrow }{P(X | A) P(A) \uparrow } \downarrow }. \uparrow \end{aligned} $$
三、贝叶斯公式的事件形式
简单版
在上一节中,我们已经接触到了贝叶斯公式:
$$ P(A | X) = \frac{P(A) P(X | A)}{P(X)} $$
证明 由条件概率的定义:
$$ P(A | X) = \frac{P(AX)}{P(X)}, \\ P(X | A) = \frac{P(AX)}{P(A)}, $$
利用 $ P(AX) $ 构造等式,
$$ P(X) P(A | X) = P(AX) = P(A) P(X | A), \\ P(A | X)= \frac{P(A) P(X | A)}{P(X)}. $$
结论得证。
复杂版
$$ P(B_{i}|A) = \frac{P(B_{i}) P(A | B_{i})}{\sum_{j=1}^{n} P(B_{j}) P(A | B_{j})}, i = 1,2, \dots, n. $$
证明 由条件概率的定义:
$$ P(B_{i} | X) = \frac{P(AB_{i})}{P(A)}, $$
对上式的分子用乘法公式、分母用全概率公式,
$$ P(AB_{i}) = P(B_{i}) P(A | B_{i}), \\ P(A) = \sum_{j=1}^{n} P(B_{j}) P(A | B_{j}), \\ P(B_{i}|A) = \frac{P(B_{i}) P(A | B_{i})}{\sum_{j=1}^{n} P(B_{j}) P(A | B_{j})}. $$
结论得证。
Note 1: 全概率公式
设
$ B_{1}, B_{2}, \cdots, B_{n}$为样本空间$ \Omega $的一个分割,即$ B_{1}, B_{2}, \cdots, B_{n}$互不相容,且$ \bigcup_{i=1}^{n} B_{i}=\Omega $,如果$ P\left(B_{i}\right)>0, i=1,2, \cdots, n, $则对任一事件 A 有$$ P(A)=\sum_{i=1}^{n} P\left(B_{i}\right) P\left(A | B_{i}\right). $$Note 2: 乘法公式(1)若
$ P(B) > 0 $,则$$ P(AB) = P(B) P(A | B). $$(2)若$ P(A_{1} A_{2} \dots A_{n-1}) > 0 $,则$$ P(A_{1} \dots A_{n}) = P(A_{1}) P(A_{2} | A_{1}) P(A_{3} | A_{1}A_{2}) \dots P(A_{n} | A_{1}A_{2} \dots A_{n-1}) $$
四、贝叶斯公式的密度函数形式
$$ \pi(\theta | X)=\frac{h(X, \theta)}{m(X)}=\frac{p(X | \theta) \pi(\theta)}{\int_{\Theta} p(X | \theta) \pi(\theta) \mathrm{d} \theta} $$
符号定义
$ X $:样本,可视为随机变量;$ \theta $:参数。参数空间中不同的参数$ \theta $对应随机变量$ X $的不同分布;$ \Theta $:参数$ \theta $的参数空间,$ \theta \in \Theta $;$ \pi(\theta) $:参数$ \theta $的先验分布。根据参数$ \theta $的先验信息确定的分布;$ \pi(\theta | X) $:参数$ \theta $的后验分布。集中了总体、样本和先验中有关$ \theta $的一切信息以后确定的分布;$ P(X | \theta) $:样本$ X $的条件概率函数。$ X $和$ \theta $都被视作随机变量,其中$ \theta $是参数。它表示在随机变量$ \theta $取某个给定值时总体的条件概率函数;$ h(X, \theta) $:样本$ X $和 参数$ \theta $的联合分布;$ m(X) $:样本$ X $的边际概率函数。
推导过程
从贝叶斯观点来看,样本 $ X $ 的产生要分两步走:
- 首先设想从先验分布
$ \pi(\theta) $产生一个样本$ \theta_{0} $. 这一步是“老天爷”做的,人们是看不到的,故用“设想”二字。 - 从
$ P(X | \theta_{0}) $中产生一组样本。这时样本$ X = (x_{1}, \dots , x_{n}) $的联合条件概率函数为$$ p\left(\boldsymbol{X} | \theta_{0}\right)=p\left(x_{1}, \cdots, x_{n} | \theta_{0}\right)=\prod_{i=1}^{n} p\left(x_{i} | \theta_{0}\right) $$这个分布综合了总体信息和样本信息。
由于 $ \theta_{0} $ 是设想出来的,仍然是未知的,它是按先验分布产生的。为把先验信息综合进去,不能只考虑 $ \theta_{0} $,对 $ \theta $ 的其他值发生的可能性也要加以考虑,故要用 $ \pi(\theta) $ 进行综合。这样一来,样本 $ X $ 和 参数 $ \theta $ 的联合分布为
$$ h(X, \theta) = p(X | \theta) \pi(\theta) $$
我们的目的是要对未知参数 $ \theta $ 作统计推断,在没有样本信息时,我们只能依据先验分布对 $ \theta $ 作出推断。在有了样本观测值$ X = (x_{1}, \dots , x_{n}) $ 之后,我们应依据 $ h(X, \theta) $ 对 $ \theta $ 作出推断。若把 $ h(X, \theta) $ 作如下分解:
$$ h(X, \theta) = p(\theta | X) m(X) $$
其中 $ m(X) $ 是 $ X $ 的边际概率函数
$$ m(\boldsymbol{X})=\int_{\boldsymbol{\Theta}} h(\boldsymbol{X}, \boldsymbol{\theta}) \mathrm{d} \theta=\int_{\boldsymbol{\Theta}} p(\boldsymbol{X} | \boldsymbol{\theta}) \pi(\boldsymbol{\theta}) \mathrm{d} \theta $$
它与 $ \theta $ 无关,或者说 $ m(X) $ 中不含 $ \theta $ 的任何信息。因此能用来对 $ \theta $ 作出推断的仅是条件分布 $ \pi(\theta | X) $,它的计算公式是
$$ \pi(\theta | X)=\frac{h(X, \theta)}{m(X)}=\frac{p(X | \theta) \pi(\theta)}{\int_{\Theta} p(X | \theta) \pi(\theta) \mathrm{d} \theta} $$
这个条件分布称为 $ \theta $ 的后验分布,它集中了总体、样本和先验中有关 $ \theta $ 的一切信息。它就是用密度函数表示的贝叶斯公式,是用总体和样本对先验分布 $ \pi(\theta) $ 作调整的结果。后验分布 $ h(X, \theta) $ 要比先验分布 $ \pi(\theta) $ 更接近 $ \theta $ 的真实情况。
(以上推导过程来自《概率论与数理统计教程》第二版 P334)
Note 1: 概率密度函数
离散随机变量取各个值的概率可以用概率分布列表示。而连续随机变量的一切可能取值充满某个区间
$ (a, b) $,在这个区间内有无穷不可列个实数,因此描述连续随机变量的概率分布不能用分布列形式表示,而要用概率密度函数表示。概率密度函数用
$ p(x) $表示。这里,$ p(x) $的值不是概率,它表示的是当$ X = x $时,概率分布的密集程度。如果用$ P(X = x) $表示随机变量$ X $取值为$ x $的概率,则$ P(X = x) \equiv 0. $(实数域的完备性+概率的可列可加性)
$ p(x) $的值虽不是概率,但乘以微分元$ dx $就可得小区间$ (x, x + dx) $上概率的近似值,即$$ p(x)dx \approx P(x < X < x+dx) $$很多相邻的微分元的积累就得到了$ X $在某个区间$ (a, b) $上的概率,即$$ \int_{a}^{b} p(x) \mathrm{d} x = P(a < X < b). $$特别地,在$ (-\infty, x) $上的积分就是分布函数$ F(x) $,即$$ \int_{-\infty}^{x} p(t) \mathrm{d} t = F(x) $$概率密度函数由分布函数以如下形式严格定义。定义 设随机变量
$ X $的分布函数为$ F(x) $,如果存在实数轴上的一个非负可积函数$ p(x) $,使得对任意实数$ x $有$$ F(x) = \int_{-\infty}^{x} p(t) \mathrm{d} t $$则称$ p(x) $为$ X $的概率密度函数。由上式,可从分布函数求得密度函数。在
$ F(x) $导数存在的点上有$$ F'(x) = p(x) $$Note 2: 联合密度函数
在有些随机现象中,对每个样本点
$ \omega $只用一个随机变量去描述是不够的。比如研究儿童的生长发育情况,仅研究儿童的身高$ X_{1}(\omega) $或仅研究其体重$ X_{2}(\omega) $都是局部的,有必要把$ X_{1}(\omega) $和$ X_{2}(\omega) $当作一个整体来考虑,讨论它们总体变化的统计规律性,进一步可以讨论$ X_{1}(\omega) $和$ X_{2}(\omega) $之间的关系。上述例子中的
$ X_{1}(\omega) $和$ X_{2}(\omega) $被称作二维随机变量。下面我们给出n维随机变量的定义。定义 如果
$ X_{1}(\omega), X_{2}(\omega), \dots , X_{n}(\omega) $是定义在同一个样本空间$ \Omega = \{ \omega \} $上的n个随机变量,则称$$ X(\omega) =(X_{1}(\omega), X_{2}(\omega), \dots , X_{n}(\omega)) $$为n维随机变量。注意:多维随机变量定义的关键是定义在同一样本空间上,对于不同样本空间
$ \omega_{1} $和$ \omega_{2} $上的两个随机变量,我们只能在乘积空间$ \Omega_{1} \times \Omega_{2} = \{ (\omega_{1}, \omega_{2}): \omega_{1} \in \Omega_{1}, \omega_{2} \in \Omega_{2} \} $及其事件域上讨论它们。联合分布列和联合密度函数由联合分布函数定义。因此先介绍联合分布函数。
定义 对任意的n个实数
$ x_{1}, x_{2}, \dots , x_{n} $,则$ n $个事件$ \{ X_{1} \leqslant x_{1} \}, $$ \{ X_{2} \leqslant x_{2} \}, $$ \dots , $$ \{ X_{n} \leqslant x_{n} \} $同时发生的概率$$ F(x_{1}, x_{2}, \dots , x_{n}) = P(X_{1} \leqslant x_{1}, X_{2} \leqslant x_{2}, \dots , X_{n} \leqslant x_{n} ) $$称为 n 维随机变量$ (X_{1}, X_{2}, \dots , X_{n}) $的联合分布函数。二元离散随机变量用联合分布列表示两事件同时发生的概率。二元连续随机变量用联合密度函数表示两事件同时发生的概率的密集程度。
定义 如果存在二元非负函数
$ p(x, y) $,使得二维随机变量$ (X, Y) $的分布函数$ F(x, y) $可表示为$$ F(x, y) = \int_{-\infty}^{x} \int_{-\infty}^{y} p(u,v) \mathrm{d}v \mathrm{d}u, $$则称$ (X, Y) $为二维连续随机变量,称$ p(u, v) $为$ (X, Y) $的联合密度函数。在
$ F(x, y) $偏导数存在的点上有$$ p(x, y)=\frac{\partial^{2}}{\partial x \partial y} F(x, y). $$Note 3: 边际密度函数
二维联合分布函数含有丰富的信息,主要有以下三方面信息:
- 每个分量的分布,即边际分布;
- 两个分量之间的关联程度,可用协方差和相关系数来描述;
- 给定一个分量的分布时,另一个分量的分布,即条件分布。
定义 如果在二维随机变量
$ (X, Y) $的联合分布函数$ F(x, y) $中令$ y \rightarrow \infty $,由于$ \{ Y < \infty \} $为必然事件,故可得$$ \lim_{y \rightarrow \infty} F(x, y)=P(X \leqslant x, Y<\infty)=P(X \leqslant x) $$这是由$ (X, Y) $的联合分布函数$ F(x, y) $求得的$ X $的分布函数,被称为$ X $的边际分布,记为$$ F_{X}(x) = F(x, \infty). $$类似地,在$ F(x, y) $中令$ x \rightarrow \infty $,可得$ Y $的边际分布$$ F_{Y}(y) = F(\infty, y). $$在二维离散随机变量中,利用联合分布求得的某分量的分布列,称作边际分布列。在二维连续随机变量中,求得的某分量的密度函数,称作边际密度函数。
定义 如果二维连续随机变量
$ (X, Y) $的联合密度函数为$ p(x, y) $,因为$$ \begin{aligned} &F_{X}(x)=F(x, \infty)=\int_{-\infty}^{x}\left(\int_{-\infty}^{\infty} p(u, v) \mathrm{d} v\right) \mathrm{d} u=\int_{-\infty}^{x} p_{X}(u) \mathrm{d} u,\\ &F_{Y}(y)=F(\infty, y)=\int_{-\infty}^{y}\left(\int_{-\infty}^{\infty} p(u, v) \mathrm{d} u\right) \mathrm{d} v=\int_{-\infty}^{y} p_{Y}(v) \mathrm{d} v, \end{aligned} $$其中$ F_{X}(x) $和$ F_{Y}(y) $分别为$$ \begin{aligned} &p_{X}(x)=\int_{-\infty}^{\infty} p(x, y) \mathrm{d} y,\\ &p_{Y}(y)=\int_{-\infty}^{\infty} p(x, y) \mathrm{d} x. \end{aligned} $$它们恰好处于密度函数位置,故称上式给出的$ p_{X}(x) $为$ X $的边际密度函数,$ p_{Y}(y) $为$ Y $的边际密度函数。由联合密度函数求边际密度函数时,要注意积分区域的确定。
Note 4: 统计推断
统计推断是根据样本信息对总体分布或总体的特征数进行推断。
五、贝叶斯估计
贝叶斯估计是参数估计的一种。
定义 使用后验分布 $ \pi(\theta | X) $ 的均值作为 $ \theta $ 的点估计,被称为后验期望估计,简称贝叶斯估计,记为 $ \hat{\theta}_{B} $。
Note 1: 点估计
定义 设
$ x_{1}, \dots , x_{n} $是来自总体的一个样本,用于估计未知参数$ \theta $的统计量$ \hat{\theta} = \hat{\theta}(x_{1}, \dots , x_{n}) $称为$ \theta $的点估计。Note 2: 无偏估计
定义 设
$ \hat{\theta} = \hat{\theta}(x_{1}, \dots , x_{n}) $是$ \theta $的一个估计,$ \theta $的参数空间为$ \Theta $,若对任意的$ \theta \in \Theta $,有$$ E_{\theta}(\hat{\theta}) = \theta , $$则称$ \hat{\theta} $是$ \theta $的无偏估计,否则称为有偏估计。
贝叶斯假设
假如我们在试验前对事件没有什么了解,从而对其参数 $ \theta $ 也没有任何信息。在这种场合,贝叶斯本人建议采用“同等无知”原则使用均匀分布作为参数 $ \theta $ 的先验分布。下面用一个实例计算此种情形下 $ \theta $ 的贝叶斯估计。
实例1 设某事件 A 在一次试验中发生的概率为 $ \theta $,为估计 $ \theta $,对试验进行了n次独立观测,其中事件 A 发生了 $ X $ 次,显然 $ X | \theta \sim b(n, \theta) $,即
$$ P(X=x | \theta)=\left(\begin{array}{l}{n} \\ {x}\end{array}\right) \theta^{x}(1-\theta)^{n-x}, \quad x=0,1, \cdots, n $$
采用“同等无知”原则,用均匀分布 $ U(0, 1) $ 作为概率 $ \theta $ 的先验分布 $ \pi(\theta) $。
$$ \pi(\theta) = \left\{\begin{array}{l} {\frac{1}{b - a}, a < x < b} \\ {0, 其他} \end{array}\right. $$
由此可利用贝叶斯公式求出 $ \theta $ 的后验分布。步骤如下:
- 写出
$ X $和$ \theta $的联合密度函数(联合分布列):$$ h(x, \theta)=\left(\begin{array}{l}{n} \\ {x}\end{array}\right) \theta^{x}(1-\theta)^{n-x}, \quad x=0,1, \cdots, n, \quad 0<\theta<1 $$ - 由边际密度函数的定义,求
$ X $的边际分布列:$$ m(x)=\left(\begin{array}{l}{n} \\ {x}\end{array}\right) \int_{0}^{1} \theta^{x}(1-\theta)^{n-x} \mathrm{d} \theta=\left(\begin{array}{l}{n} \\ {x}\end{array}\right) \frac{\Gamma(x+1) \Gamma(n-x+1)}{\Gamma(n+2)} $$其中$ \Gamma(x) $为伽马(Gamma)函数。 - 由贝叶斯公式,求
$ \theta $的后验分布的密度函数:$$ \begin{aligned} \pi(\theta | x) &=\frac{h(x, \theta)}{m(x)} \\ &=\frac{\Gamma(n+2)}{\Gamma(x+1) \Gamma(n-x+1)} \theta^{(x+1)-1}(1-\theta ^{(n-x+1)-1}, \quad 0<\theta<1 \end{aligned} $$ - 最后求后验分布的均值
$ E(\theta | x) $。由$ \theta $的后验分布的密度函数$ \pi(\theta | x) $的形式,我们发现$ \theta | x \sim B e(x+1, n-x+1) $。由贝塔分布$ X \sim Be(a, b) $的数学期望计算公式,可得:$$ E(X) = \frac{a}{a + b} = \frac{x + 1}{n + 2} $$
(以上推导过程来自《概率论与数理统计教程》第二版 P335)
假如不用先验信息,只用总体信息与样本信息,那么事件 A 发生的概率的最大似然估计为
$$ \hat{\theta}_{M} = \frac{x}{n} $$
事实证明,以均匀分布作为参数 $ \theta $ 的先验分布的贝叶斯估计并没有退化为最大似然估计。那么最大似然估计和贝叶斯估计有什么区别呢?
某些场合,贝叶斯估计要比最大似然估计更合理一点。比如,在产品抽检中只区分合格品和不合格品,$ \theta $ 表示合格品率。则该过程可看作 n 次随机抽样,由 实例1 可知,$ \theta $ 的贝叶斯估计为 $ \hat{\theta}_{B} = \frac{x + 1}{n + 2} $。而最大似然估计为 $ \hat{\theta}_{M} = \frac{x}{n} $。在抽检中,“抽样三次全为合格品”和“抽检十次全为合格品”这两个事件在人们心目中的印象是不同的,后者的质量比前者更信得过。这种差别在合格品率 $ \theta $ 的最大似然估计 $ \hat{\theta}_{M} $ 中反映不出(两者都是1)。而 $ \hat{\theta}_{B} $ 分别是 (3+1)/(3+2)=0.8 和 (10+1)/(10+2)=0.917。由此可以看到,贝叶斯估计更符合人们的理念。
FAQ
Q: 参数估计中的“参数”指的是什么?
A: “参数”指如下三类未知参数:
- 分布中的未知参数
$ \theta $;- 分布中的未知参数
$ \theta $的函数;- 分布的各种特征数。
Q: 参数估计的目的是什么?
A: 参数估计的目的是估计参数
Q: 进行参数估计之前需要哪些信息?
A: 我们需要参数
$ \theta $的后验分布。任何关于$ \theta $的统计推断都应该基于$ \theta $的后验分布。Q: 除了贝叶斯估计,还有哪些参数估计的方法?
$$ 参数估计 \left\{\begin{array}{l} {点估计} \\ {矩估计} \\ {最大似然估计} \\ {最小防方差无偏估计} \\ {区间估计} \\ { \dots } \end{array}\right. $$

六、探索:联合分布蕴含的信息
#todo
参考书籍:
- 《贝叶斯方法:概率编程与贝叶斯推断》
- 《概率论与数理统计教程》